Inequalities and Limit Theorems
Two very useful inequalities
**Markov's Inequality**:
If X takes on only nonnegative values, then for any a>0

proof:

**Chebyshev's Inequality:**
If X is a r.v. with mean μ and variance σ^2, then for any k>0:

proof:

**Example** Consider the uniform random variable with f(x) = 1 if 0k·0.2887)$\le$1/k^2
For example
P(|X-0.5|>1·0.2887)$\le$1/1^2 = 1 (rather boring!)
or
P(|X-0.5|>3·0.2887)$\le$1/3^2 = 1/9
actually P(|X-0.5|>0.866) = 0, so this is not a very good upper bound.
**Example** Consider the discrete random variable X with P(X=0) = P(X=1) = 0.5. Now
μ = 0·0.5+1·0.5 = 0.5
E[X^2] = 0^2·0.5+1^2·0.5 = 0.5
so σ^2 = E[X^2]-μ^2 = 0.5-0.5^2 = 0.25
and so σ = √0.25 = 0.5
Now
P(|X-μ|>k·σ) =
(Weak) Law of Large Numbers
Let X_1, X_2, ... be a sequence of independent and identically distributed (iid) r.v.'s having mean μ. Then 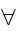&eps;>0

proof (assuming in addition that V(X_i)=σ^2 < )

We apply Chebyshev's inequality to Z_n:

This theorem forms the bases of (almost) all simulation studies: say we want to find a parameter θ of a population. We can generate data from a random variable X with pdf (density) f(x|θ) such that Eh(X) = θ. Then by the law of large numbers

**Example** : in a game a player rolls 5 fair dice. He then moves his game piece along k fields on a board, where k is the smallest number on the dice + largest number on the dice. For example if his dice show 2, 2, 3, 5, 5 he moves 2+5 = 7 fields. What is the mean number of fields θ a player will move?
To do this analytically would be quite an excercise. To do it via simulation is easy:
Let X be an independent random vector of length 5, with X[j] 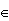 1,..,6 and P(X[j]=k)=1/6
let h(x) = min(x)+max(x), then Eh(X) = θ
Let X_1, X_2, .. be iid copies of X, then by the law of large numbers

The simulation is implemented in **exminmax**
**Example** : A company has a system (website, computers, telephone bank, machine, ...) that is mission-critical, and so they have two identical systems with the second one taking over automatically when the first one fails. From experience they know that each systems failure time has an exponential distribution with mean 84.6 hours. Once a system is down its repair time has a U[1,5] distribution. What is the probability that both systems are down simultaneously?
Note: there is the possibility that both systems go down, system 1 gets fixed but breaks again before system 2 is fixed, so that they both are down immediately. The probability of this happening is so small though that we will ignore this.
Let Ti, i=1,2 be the failure time of system i. Let R be the repair time of system 1. Then the probability of both systems being down is P(R > T2) = P(R-T2>0) = E[I(0, )(R-T2)]
So we have h(R,T2) = I(0, )(R-T2)
The simulation is implemented in **exsystems1**
Example , cont. What is the mean time per year when both systems are down?
Let Ti(k) be the failure times of system i in order with k=1 the first time, k=2 the second time etc.. Let R(k) be the same for the repair time. So we are looking at a sequence T1(1), R(1),T1(2), T2(2) etc.

The simulation is implemented in **exsystems2**
Example , cont. Say the company has the option to contract another repair man, which would lower the repair time such that then R~U[1,3]. It costs the company $8950 per hour when the system is down. How much can they pay this new repair man so it is a good idea to contract him?
We found that without the new guy we have a downtime of about 6 hours per year for a yearly cost of $53700. If we higher the new guy we have an annual downtime of about 2.5 hours for a total cost of $22400. So if we should pay him at most $31300 per year.
Example , cont. Say we have a contract with our main customer that specifies that our downtime can not exceed 10 hours per year, otherwise we have to pay a fine. We decide we are willing to accept a 10% chance that we exceed the time limit. Should we proceed with these conditions?
The simulation is implemented in **exsystems3** We see that there is about a 15% chance of the failure time exceeding 10 hours, so we should not proceed.
Central Limit Theorem
This is one of the most famous theorems in all of mathematics / statistics. Without it, Statistics as a science would not have existed until very recently:
We first need the definition of a normal (or Gaussian) r.v.:
A random variable X is said to be normally distributed with mean μ and variance σ^2 if it has density:

If μ=0 and σ=1 we say X has a standard normal distribution.
We use the symbol Φ for the distribution function of a standard normal r.v., so

Let X_1, X_2, .. be an iid sequence of r.v.'s with mean μ and standard deviation σ. Then

where  is the sample mean of the first n observations.
Note that

so the scaling in the clt is just right to match the standard normal r.v.
Let's do a simulation to illustrate the CLT: we will use the most basic r.v. of all, called a Bernoulli r.v. which has P(X=0)=1-p and P(X=1)=p (Think indicator function for the coin toss}. So we sample n Bernoulli r.v. with "success paramater p" and find their sample mean. Note that

The simulation is done in the routine **cltexample 1**
Let's return to the Example of the company with the mission-critical system above. Let D be the total downtime per year. D has some strange distribution, but it also is the sum of independent random variables, although they are not iid because some of them are exponentials and others are uniform. In **exsystems4** we rerun the simulation in **exsystem3**, and this time we also find the sample mean and standard deviation of the simulated D's. Finally we overlay the histogram (scaled to integrate to 1) with the corresponding density. The histogram shows that D is somewhat normal anyway.
We find μD=6.0 and σD=4.0. So

Approximation Methods
Say we have a r.v. X with density f, a function h and we want to know V(h(X)). Of course by definition we have

but sometimes these integrals (sums) are very difficult to evaluate. In this section we discuss some methods for approximating the variance.
Recall: If a function h(x) has derivatives of order r, that is if g(r)(x) exists, then for any constant a the **Taylor polynomial** of order r is defined by
-Tr(x) goes to 0 faster than the highest order term:
**Taylor's theorem**

There are various formulas for the remainder term, but we won't need them here.
**Example** : say h(x) = log(x+1) and we want to approximate h at x=0. Then we have

The approximation is illustrated in **taylor**
For our purposes we will need only first-order approximations (that is using the first derivative) but we will need a multivariate extension as follows: say X1, ..,Xn are r.v. with means μ1, .. ,μn and define **X**=(X1, ..,Xn) and **μ**=(μ1, .. ,μn). Suppose there is a differentiable function h(**X**) for which we want an approximate estimate of the variance. Define

The first order Taylor expansion of h about **μ** is

Forgetting about the remainder we have

and
. For example when you roll a fair die the odds of getting a six are (1/6)/(1-(1/6) = 1:5.
An obvious estimator for p is , the sample mean, or here the proportion of "successes" in the n trials. Then an obvious estimator for the odds is /(1-). The question is, what is the variance of this estimator?
Using the above approximation we get the following: let h(p)=p/(1-p), so h'(p)=1/(1-p)2 and

The routine **varapp1** illustrates how good an approximation this is.
**Example** : We have a rv X~U[0,1], and a rv Y~U[0,X]. Find an approximation of V[Y/(1+Y)]
Note: this is called a hierarchical model.
We have:
1) f_X(x)=1 if 0